RunLoop 是 iOS 事件机制的核心,在缺少实践的情况下,看了几篇相关博文后感觉还是隔靴搔痒,没有参透。今天刚好有空看了一下 Node.js,发现 Node.js 的 EventLoop 机制和 iOS 的 RunLoop 异曲同工,在理解 EventLoop 之后,一些 iOS 相关的疑惑也触类旁通了。
Node.js 特征
单线程、异步 I/O 、事件触发机制是 Node.js 有别与其他后端技术的重要特征。与前端、客户端不同,后端属于 I/O 密集型,比如文件读取、数据库查询等长时间 I/O 操作,在这种情况下,如何提高 CPU 利用率就是后端技术用来增加吞吐量、提升效率的重要手段。
多线程同步模型 VS 单线程异步模型
使 CPU 尽量满负荷工作的方法很多,这里选择了两个对立的模型作分析对比,一类是基于阻塞式的多线程同步模型,另一类是基于非阻塞式的单线程异步模型。
为理解这两类情况,我们可以用生活中排队挂号的例子来类比。假如挂号处的 KPI 是在一定时间内处理越多的挂号业务越好,一次挂号操作包括医生打印付费单、病人掏钱和医生收钱三个动作,其中病人掏钱可以看做一次 I/O 操作,需要等待未知时间,而另外两个医生的操作可以看做 CPU 操作,动作迅速高效。对于同一个医生,有两种模型可以实现。
一是切换设备,医生每处理完打印操作就切换到下一台设备,为下一个病人打印,直到一圈转完后回到第一个病人那里完成剩余的收钱操作,以此类推。可以发现这个过程中,医生一直处于忙碌状态,并没受到病人掏钱中断的影响。二是切换病人,医生每处理完打印操作就让这个病人到别处去掏钱,等病人掏出钱来再插到原来的队伍中,完成剩余的收钱操作。在这个过程中,医生同样一直忙碌。
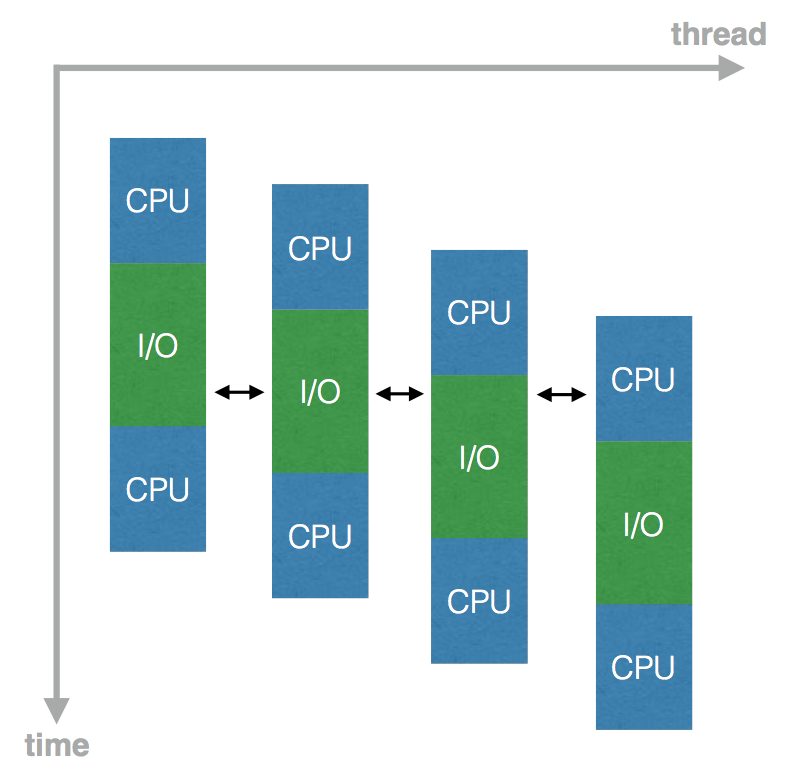
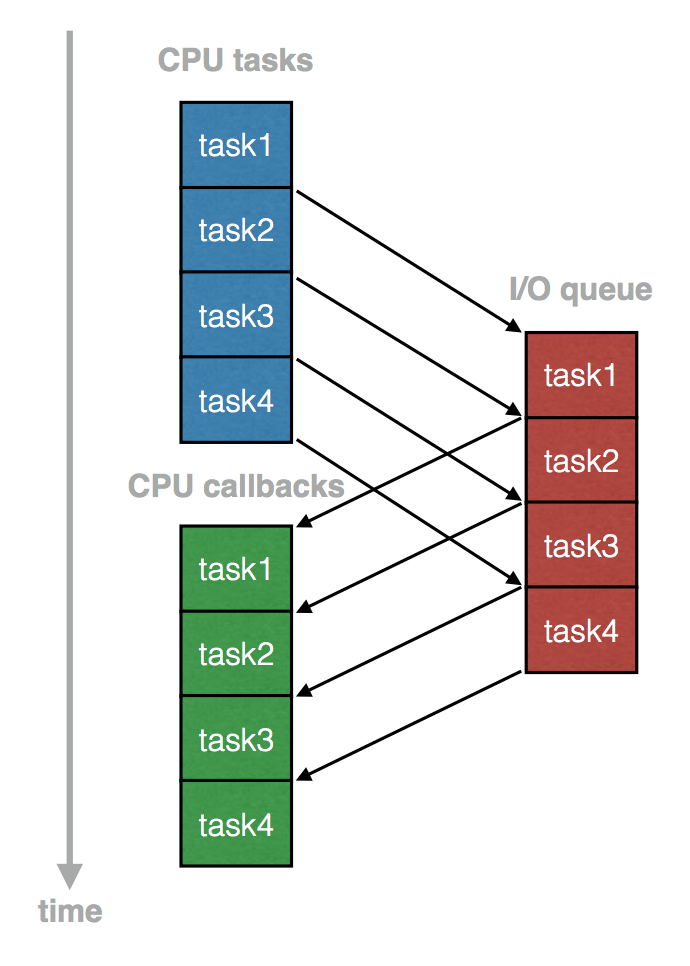
第一种方式其实就是多线程操作,优点是对单个事件而言,执行的顺序依然是阻塞的、同步的,执行逻辑明确、代码易于调试;缺点是上下文频繁的切换、资源的申请和回收、现场的保护和恢复都是一些额外开销。第二种方式也就是 Node.js 的单线程异步模型,在同样 CPU 效率的情况下,免去了上面的系统开销,但是改变了以往顺序执行的思维,也对调试带来一些麻烦。
事件触发机制
再借用一下刚才的例子,在单线程异步模型中,病人掏完钱后会发个通知告诉医生自己已经 ready,等待被重新安插回队伍中,让医生在下一个处理周期中完成剩余的收钱操作。在这个过程中,医生一直在一个循环体系中不断干活,当收到事件后触发行为。这样一类比,RunLoop 和 EventLoop 的概念也就好理解了,I/O 操作完成后,向 RunLoop 中发送消息,并把携带的参数以 callback 的形式 (block) 回调到 RunLoop 中,等待 RunLoop 的执行。
iOS RunLoop
按照上面的类比, iOS 中 RunLoop 的概念也就顺利成章地理解了。
更多细节推荐 YY 大神的深入理解RunLoop一文。