Samurai-Native 是 Hackers and Painters 出的第二款 Web-Native 框架,相对与其自家的第一款 BeeFramework 由 MVC、网络、文件系统等组成的大型框架而言,Samurai-Native 把动态 UI 下发的能力独立出来,用标准的 HTML + CSS + Javascript 技术栈提供一套混合开发的解决方案,相较而言更轻量、集成的成更低,是客户端开发向前端迁移的优秀方案之一。
Samurai-Native 支持标准的 HTML 标签,框架内转化为客户端的 Native 控件,同时也支持在 HTML 模板里直接把 Native 的控件名作为标签使用。标签的 name 属性支持动态数据绑定,布局方面支持标准 CSS 和 Flexbox 布局,事件处理采用高大上的 Signal Handling 机制。
这篇文章主要撸了一遍 Samurai-Native 框架中模板解析和样式解析的实现流程和原理,渲染和布局部分会在一下篇博客中具体分析。
整体流程
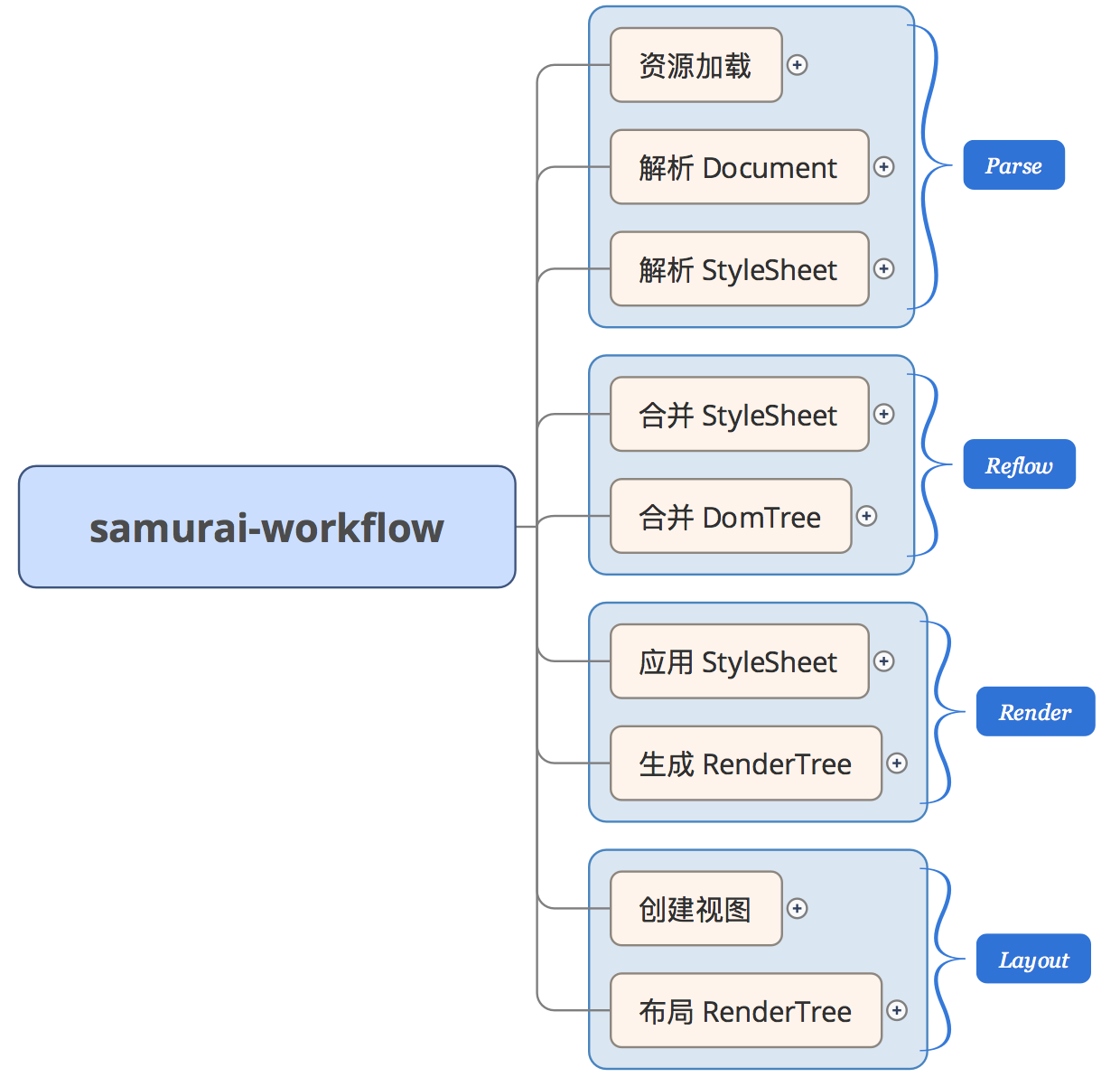
1. 解析流程
- 上层业务启动后,加载模板到 document
- 从 document 解析 HTML 资源文件,生成一棵从标签映射过来的 domTree
- 从 document 解析 CSS 资源文件,默认样式表、link 的外部样式表、type=”text/css” 定义的外联样式表和标签 style 定义的内部样式表分别解析到 document 对应对象中
2. Reflow 流程
- document 中样式有关对象合并到 styleSheet 对象中,以键值对形式按不同的匹配类型(tag / id / class)保存在词典里
- 处理 document 中外部导入的 HTML,把根节点作为 shadowRoot 绑定到相应的 domTree 节点上
3. 渲染流程
- 遍历 domTree 上每个节点(包括 shadowRoot),对不同来源的样式按照优先级依次添加到节点的 computedStyle 上,包括处理节点的继承样式,此时 的 computedStyle 还是以键值对形式存储样式,而且存的值仍然是字符串形式
- 从 domTree 映射到 renderTree,这步中根据节点的类型(document / element / text)和节点的层次(tree / branch / leaf/ hidden)生成相应的渲染对象,同时计算 computedStyle 中存储的值或者转换为 OC 对象
4. 布局流程
- 对 renderTree 上的每个节点根据 viewClass 递归创建视图,构造视图之间的层级关系,并且对视图绑定事件。
- 为视图计算尺寸和位置,并最终绘制到屏幕上。
关键类结构
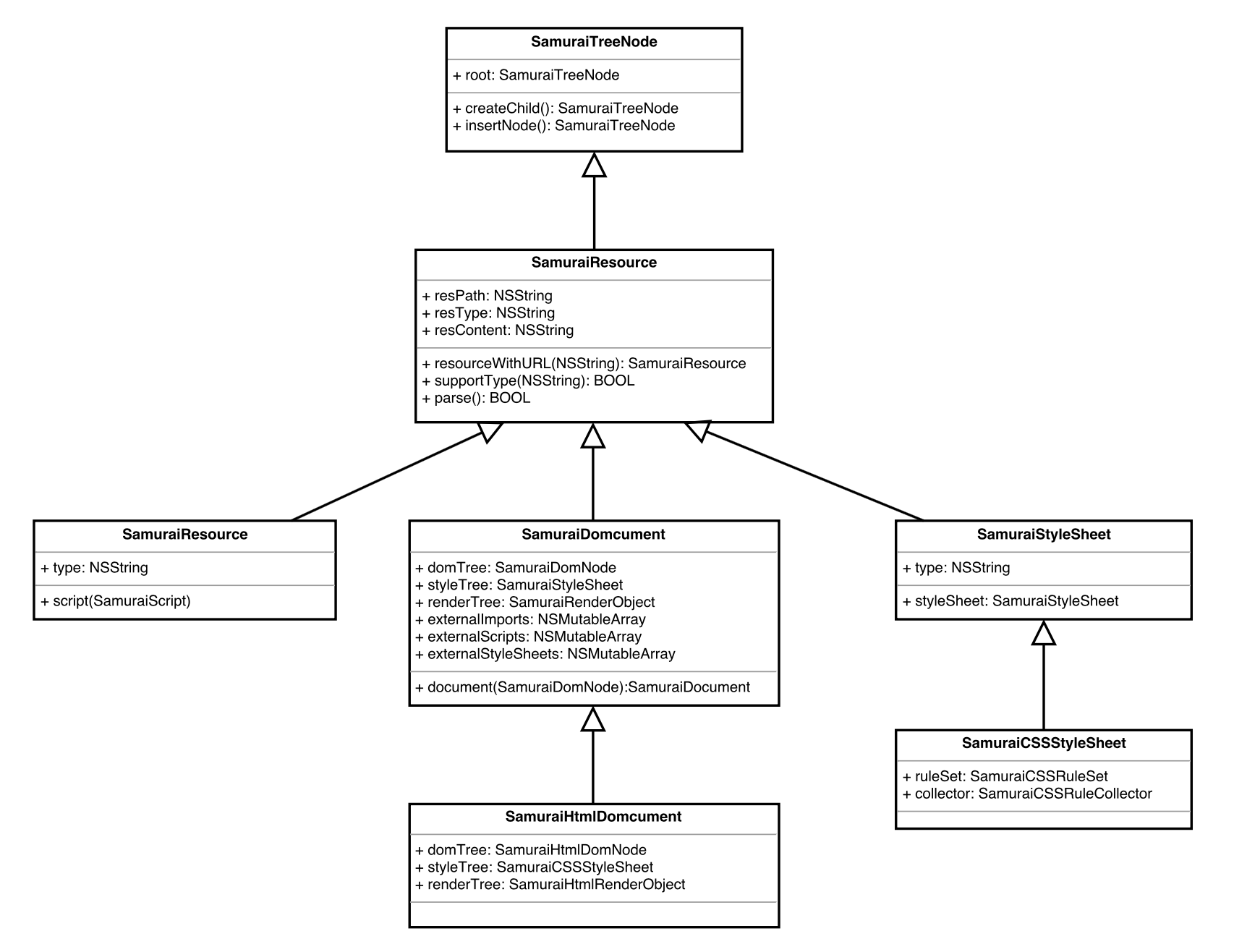
1. 祖先类 SamuraiTreeNode
- Samurai-Native 框架中与 HTML / CSS / Render / Layout 相关类放在
samurai-webcore文件目录下,其相关基础类放在samurai-framework文件目录下。 SamuraiTreeNode作为基石,放在samurai-webcore目录下,主要定义了树形结构创建及修改相关的一些方法。
2. 资源类
- 基类
SamuraiResource继承自SamuraiTreeNode,负责记录资源文件路径、内容等信息并提供一些初始化方法,同时也是SamuraiDocument、SamuraiStyleSheet和SamuraiScript的父类,这三个类分别对应模板、样式表和脚本解析后的对象。 SamuraiDocument会持有一棵从 HTML 映射来的 domTree,一个树状样式表 styleTree、一棵渲染树 renderTree,以及保存着外部导入文件externalImports、externalScripts、externalStyleSheets。- Samurai 解析实际使用的是
SamuraiHtmlDocument、SamuraiCSSStyleSheet两个类,SamuraiHtmlDocument、SamuraiCSSStyleSheet持有样式规则集SamuraiCSSRuleSet对象和规则选择器SamuraiCSSRuleCollector对象。
3. 内部树类
SamuraiDomNode和SamuraiRenderObject直接继承自SamuraiTreeNode,分别对应 document 里的 domTree 和 renderTree 树结构,前者记录节点的类型、属性、标签,还会弱引用一个SamuraiDocument对象,用来在任意时候获取自身 document 的一些信息。SamuraiDomNode的子类SamuraiHtmlDomNode是框架中实际用到的 domTree 类型,持有用于实际计算样式的 computedStyle 样式和 shadowHost。SamuraiDomNode的另一个子类SamuraiRenderObject弱引用他的 domNode,并持有一个SamuraiRenderStyle对象和一个用于实际展示的视图,他的子类SamuraiHtmlRenderObject是实际使用的类。
接下来看一下流程对应的关键调用栈。
Parse Workflow
加载资源
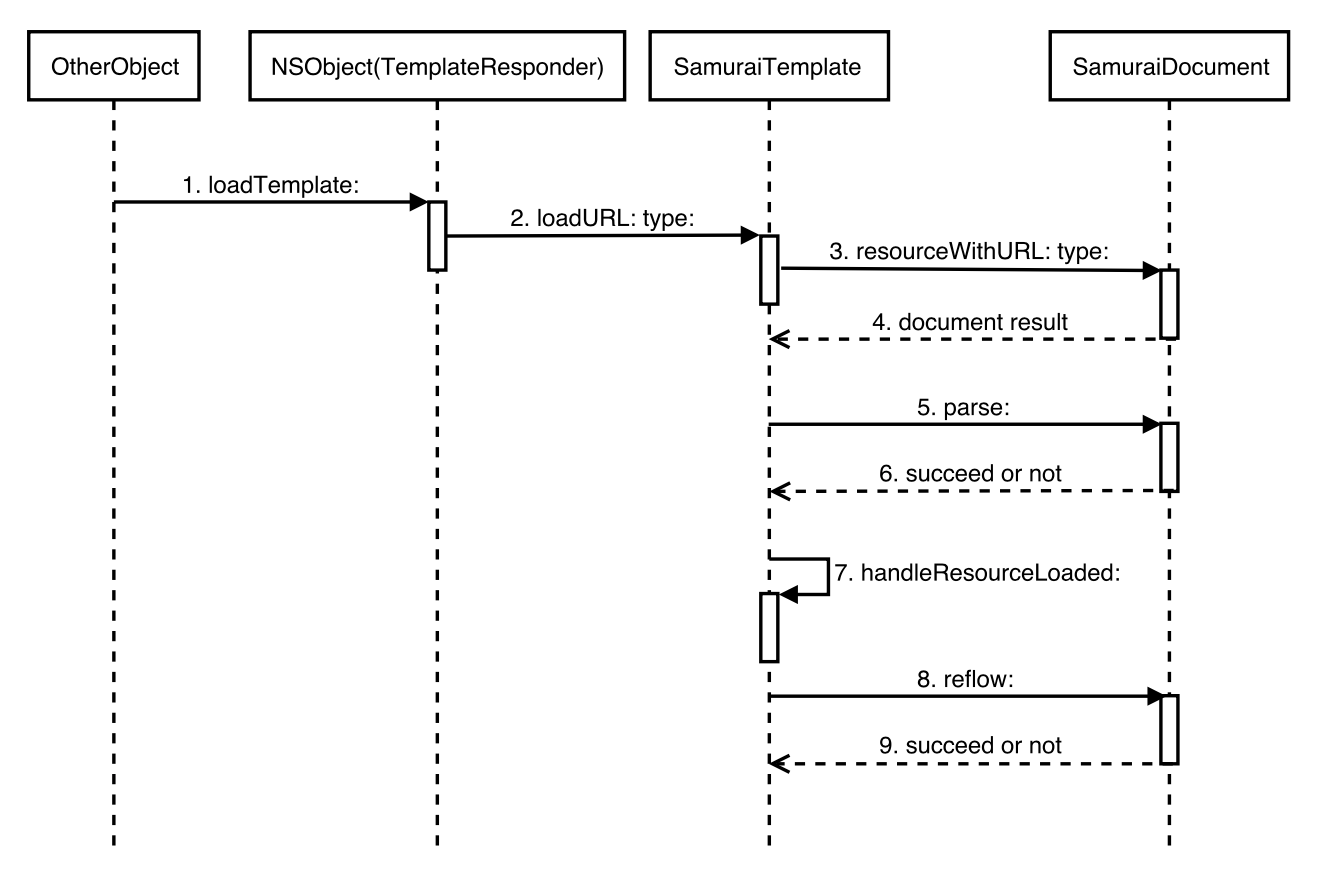
服务启动后,经过层层调用最终会执行 NSObject 的 TemplateResponder 扩展类的方法,处理本地或者网络资源加
- (void)loadTemplate:(NSString *)urlOrFile type:(NSString *)type上面的方法会对根据模板的资源路径和方式选择对应的加载方法,加载方法里先从 SamuraiDocument 父类调用创建一个相应子类的资源对象,然后解析他。比如从服务端下发的模板会调用 SamuraiTemplate 的方法
- (void)loadURL:(NSString *)url type:(NSString *)type加载方法里首先调用 SamuraiDocument 的方法返回一个 document 资源对象
+ (id)resourceWithURL:(NSString *)string type:(NSString *)type接下来会通过标志一些状态来告诉外部当前的状态,之后调用父类 SamuraiResource 的 - (BOOL)parse 方法根据资源的实际类型调用子类的解析方法,具体的解析流程接下类会分析
完成解析工作后,通过 SamuraiTemplate 的
- (void)handleResourceLoaded:(SamuraiResource *)resource方法处理资源加载后续工作,对 document 资源中的嵌套的子资源递归再走一遍上面的流程,直到 resourceQueue 中没有待加载的资源后,对 document 调用 - (BOOL)reflow 流程,具体的 reflow 过程拆分到下面分析。
解析 HTML
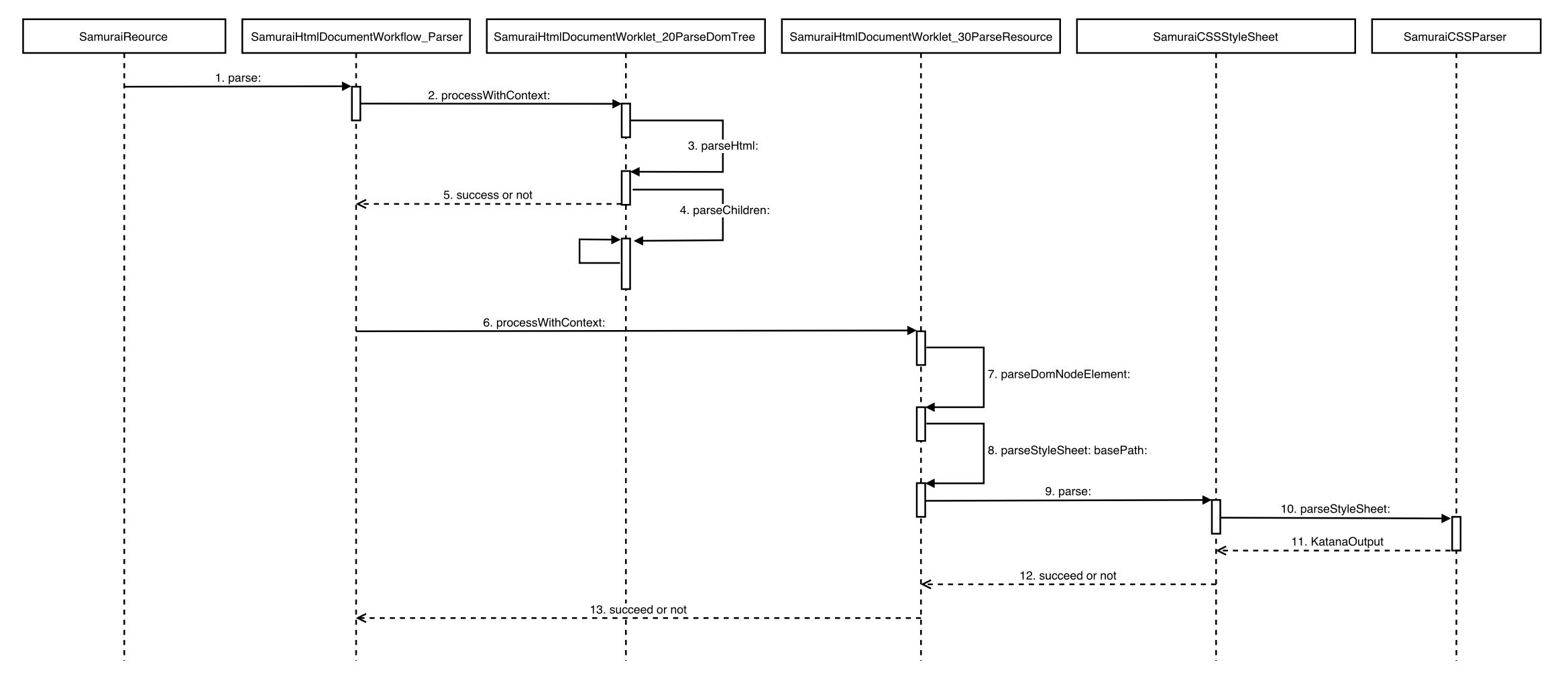
资源的解析部分是整个框架的基础,这部分的重点在于把 HTML 文件解析为 domTree,把 CSS 文件解析为 styleSheet,并且需要具备处理各种来源资源的能力。Samurai-Native 这两部分分别用了 Google 的开源 HTML 解析器 Gumbo Parser 和 CSS 解析器 Katana Parser,两者的特点都是轻量级、外部依赖少、支持标准格式,足够在客户端使用。这里插一句,在对比了 Katana Parser 和 NetSurf 浏览器的内置 LibCSS Parser 之后,发现其实 Katana 只是解析器,Samurai-Native 自己处理了选择器的功能,性能会比 LibCSS 略逊一筹。
接着看流程,加载资源完毕,SamuraiResource 调用 - (BOOL)parse 方法后,SamuraiHtmlDocumentWorkflow_Parser 根据上下文返回一个解析流程对象 parserFlow,然后调用他的 - (BOOL)process 方法,调用下面方法处理 workflow 中的每个 worklet
- (BOOL)processWithContext:(SamuraiHtmlDocument *)documentHTML 解析封装在 SamuraiHtmlDocumentWorklet_20ParseDomTree 类中,方法
- (SamuraiHtmlDomNode *)parseHtml:(NSString *)html是解析 HTML 的入口,内部经过 Gumbo 解析器的处理,生成 GumboOutput 对象,通过递归访问他的节点构成 domTree 并返回。
简单了解一下 GumboOutput 这个对象,
GumboOutput是文档解析后的输出对象,文档中的所有解析信息都用过这个数据结构间接访问,可以通过GumboNode类型的output->document访问文档对象GumboNode节点对象可以访问自己的类型,文档、元素、文本类型分别对应有一个GumboDocument、GumboElement和GumboText对象,还可以访问自己的父节点和在兄弟节点中的位置GumboElement元素节点包括指向自己子节点的GumboVector对象,标签名GumboTag和 属性GumboVector等等
在解析方法中,递归调用
- (void)parseChildren:(GumboNode *)node forParentNode:(SamuraiHtmlDomNode *)domNode解析子节点,在这个方法中,对不同类型的 GumboNode 分类讨论,比如对 GUMBO_NODE_ELEMENT 节点递归解析子节点,并把属性键值对存储在一个词典中;对 GUMBO_NODE_TEXT 节点只保存他的内容。
解析 CSS
CSS 解析部分接着看上面 timeline 的后半部分,之前说到 SamuraiHtmlDocumentWorkflow_Parser 遍历解析 parser 流程的每个 worklet,那么在处理完 SamuraiHtmlDocumentWorklet_20ParseDomTree 并得到成功解析的指令后,接下来会调用 SamuraiHtmlDocumentWorklet_30ParseResource 的方法解解析 CSS。
- (BOOL)processWithContext:(SamuraiHtmlDocument *)document按照 HTML 解析的思路,CSS 解析也分别对 document、element、text 等类型分类讨论,document 节点是文档的父节点,只用于子节点的遍历,text 节点在 Gumbo 中被认为是用于保存文本内容的,并没有样式等属性,那么只有 element 元素的解析有实际作用。
- (void)parseDomNodeElement:(SamuraiHtmlDomNode *)domNode forDocument:(SamuraiHtmlDocument *)document方法中根据 domNode.tag 分别解析样式文件,分类存储到文档的不同对象中,为不同时机的加载做准备
- 外部和内部 styleSheet 资源保存在
document.externalStyleSheets中 - 外部链接的 import 资源保存在
document.externalImports中
样式和 externalImports 在遍历的时候便做了解析,分别调用下面函数触发,
- (SamuraiStyleSheet *)parseStyleSheet:(SamuraiHtmlDomNode *)node basePath:(NSString * )basePath
- (SamuraiDocument *)parseImport:(SamuraiHtmlDomNode *)node basePath:(NSString * )basePath需要注意的是,在这两个解析方法中,按照资源的位置定义加载策略,比如 doucment 和 head 中引入的资源会第一时间预加载,而 body 中的资源会采用延时加载来提高初始化时候的解析速度。
进一步挖掘样式解析调用会发现,在下一层次中,SamuraiCSSStyleSheet 调用 - (BOOL)parse 来实际解析样式文件。其内部调用 SamuraiCSSParser 单例方法
- (KatanaOutput *)parseStylesheet:(NSString *)text把传入的资源内容解析为 Katana 解析器的输出对象 KatanaOutput,然后把解析出的规则添加到 SamuraiCSSRuleSet 集合对象中,这个对象会和 SamuraiCSSRuleCollector 联合选择出 domTree 上每个节点的样式,具体的规则放在渲染部分再分析。
简单了解一下 Katana 的数据结构
KatanaOutput中的KatanaStyleSheet保存解析得到的样式表,内部由规则集组成- 每一条规则
KatanaRule包含名字和规则类型(style/media/value/selector/declaration)KatanaRuleType,不同类型的规则有对应的数据结构去细化。我们这里主要看对 styleSheet 的解析。 KatanaSelector数据结构中存储着用于匹配规则类型的KatanaSelectorMatch,包括 tag/id/class/pseuduoClass等,在SamuraiCSSRuleSet中调用
- (BOOL)findBestRuleSetAndAddWithSelector:(KatanaSelector *)selector ruleData:(SamuraiCSSRule *)ruleData通过 selector->match 可以得到当前 rule 的匹配类型,对 styleSheet 解析得到的每个规则按匹配类型分门别类存放,用于之后分配各 domNode 的样式。
Reflow Workflow
接着之前的流程,对 document 调用 - (BOOL)parse 成功返回后,会紧接着调用 document 的 - (BOOL)reflow 方法。Reflow 部分的工作就是整合之前加载的各路资源,一是合并样式表,二是合并 domTree。
合并 StyleSheet
经过资源加载,样式表可以分成四类:
- 预置在本地的默认样式表
html.css和html+native.css,存储在[SamuraiHtmlUserAgent sharedInstance].defaultStyleSheets里。html.css里定义了标准 HTML 标签的基础样式,html+native.css里定义了桥接的原生控件的基础样式 - 定义在模板里的样式表,也就是在 CSS 解析中我们拿到的 styleTree
- 模板中通过外部链接形式导入的样式表,在 CSS 解析时遍历 domTree 的过程中我们把遇到的外部样式表保存在
document.externalStylesheets document.externalImports里链接的样式表
在 SamuraiHtmlDocumentWorklet_40MergeStyleTree 的
- (BOOL)processWithContext:(SamuraiHtmlDocument *)document方法里,解析完的第一类和第三类 styleSheet 调用 SamuraiCSSStyleSheet 的
- (void)merge:(SamuraiCSSStyleSheet *)styleSheet方法合并到 document 的 styleTree 中,这里的合并方法封装了 SamuraiCSSRuleSet 的方法,
- (void)addStyleRules:(KatanaArray *)childRules把规则按解析出的匹配规则分类放到 styleTree 的各规则集合中。
合并 DomTree
在合并 styleSheet 时我们遇到的 document.externalImports 文件是自定义组件通过
<link rel="import" href="component.html" >的形式链接进 document 的,component.html 里封装了组件的模板、样式和脚本,对外部来说就是黑盒调用,也就是通常说的 Shadow DOM。
合并 domTree 的过程就是把 Shadow DOM 合并进来,在 SamuraiHtmlDocumentWorklet_50MergeDomTree 类中,把document.externalImports 里每个资源文件的根节点作为 domNode.shadowRoot 绑定到 domTree 的对应节点上。
到这里,模板解析、样式解析以及 reflow 的 workflow 已经完成,渲染和布局的解析请移步下一篇博客 Samurai-Native 渲染及布局原理。